DPS数据处理系统v16.05
完善的统计分析功能涵盖了几乎所有的统计分析内容,是目前国内统计分析功能最全软件包。但我们仍然期待着您的建议,不断地吸纳新的统计方法,使DPS系统的统计分析功能更加完善。
更新日志
DPS系统聚类图作图功能改进
发布日期:2013-11-25在Q-型聚类、在0-1型数据聚类、R-型聚类、信息聚类、以及模糊数据聚类,其系统聚类图的显示形式相同。系统聚类图作图功能,根据用户要求进行了改进。以下面某县气候自然生态的Q型聚类分析为例:将数据一行为一个样本,一列为一个变量,按如下格式编辑数据:

编辑数据之后用鼠标选中待分析的数据(图1),然后执行"系统聚类分析"功能。在分析过程中,系统会出现如下含两个页面的用户对话框(图2)。其中的第一个页面是系统聚类数据处理、聚类方法选择界面。这里用户可选择数据转换方法、聚类距离计算和系统聚类图产生方法(图2)。
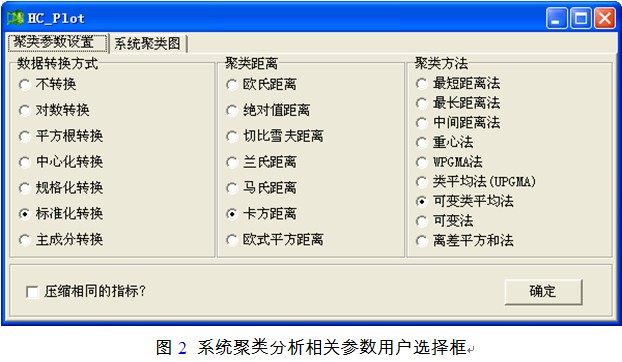
第2个页面是供用户对系统聚类图进行编辑处理操作。该页面中部显示了当前参数状态下的系统聚类图。聚类图缺省方式为图3形式:
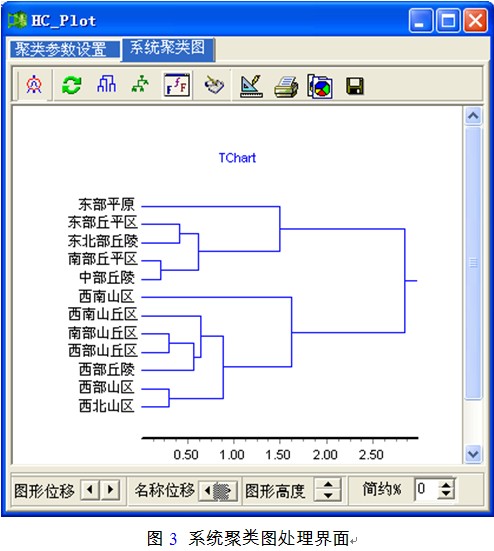
中间是聚类图,上部是功能按钮,下部是调整图形显示的标尺。系统聚类图上部的一组快捷按钮可对图形进行设置、处理。
1.左边的第一个按钮可控制聚类图输出形式。点击该按钮后,得到聚类图如图4a所示,这时可以在图像下部设置聚类图圆弧角度。得到不同圆弧大小的系统聚类图。
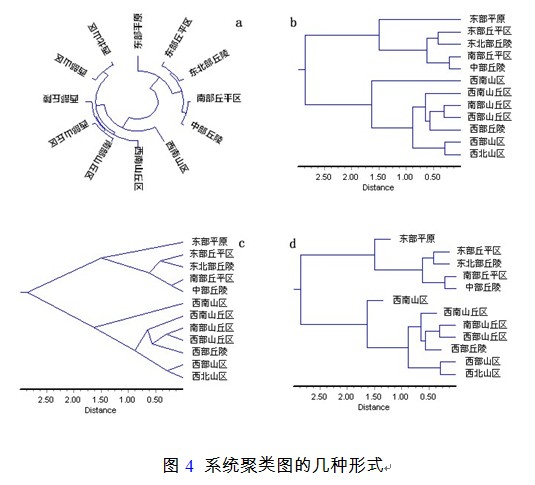
2.第二个按钮可以控制聚类图左右反转。在图3方式下点击该按钮,得到的聚类图的形式如图4b。
3.第三个按钮控制聚类图是否是树枝图形式,在系统聚类图处于图4b形式时点击该按钮,得到的系统聚类图形式如图4c。
4.第四个按钮控制聚类图中的名称是否是阶梯状显示,同样在图4b形式下点击该按钮,得到的聚类图的形式如图4d。
5.第五个按钮可以设置各个样本名称显示的字体、字号和颜色。
6.对系统聚类图更细致的修改,如对聚类图中的线条、样本名称格式的设置,可点击 按钮。这时进入系统聚类图编辑界面(图5)。
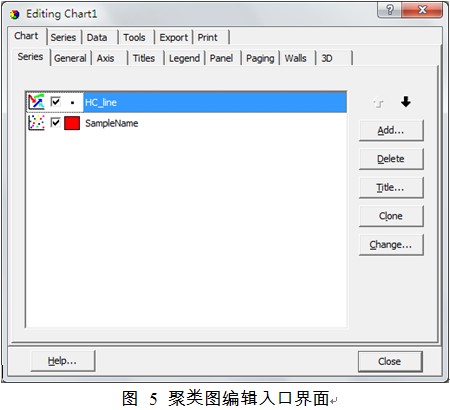
线条显示的设置:在聚类图编辑界面双击HC_line,然后点击Formats→Color,在颜色选择界面里选择您所希望的颜色,返回后系统即显示您选定的颜色。如点击Formats→Border,会进入线条格式(实线虚线、线条粗细)选择框,这里可设置线条的各种类型。
样本名称显示设置:在聚类图编辑界面双击SampleName,然后点击Marks→Text→Font,这时系统会弹出样本名称字体设置界面。在这里,您可对字体字号、字的颜色进行设置,返回后系统即显示您选的字体。
系统聚类图的高度,可通过下方的快捷按钮进行控制。如果样本名称在图中的显示位置不很合适,则可通过图形位移和名称位移两个按钮,左右调整,调整他们到合适位置。
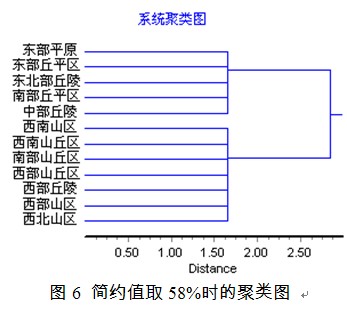
简约百分数可以对距离小于一定百分比例的点进行简约地显示,如对图3,简约百分数调整到58%,这时聚类图显示形式如下:
如果对初始聚类谱系图,点击第一个按钮,并将圆弧角度定为180度,则可得到图7的显示式样。
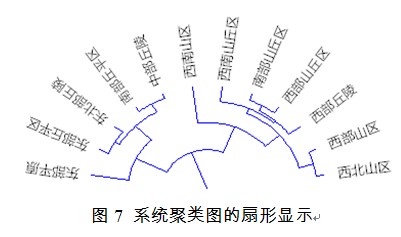
图形处理结束时,点击右上角的退出按钮,系统聚类树状图会插入在电子表格中。电子表格里的图片,用鼠标点击一下,再按右按钮,选择"复制",就能将图片粘贴到Word等文档处理的工具里面。根据教材中系统聚类图例子数据作图。适当变换后亦可得到如下3种显示形式。

非线性回归模型参数全局优化算法重大进展
发布日期:2013-05-01目前几乎所有数据统计、建模软件,非线性回归参数拟合,强烈地依赖于用户提供适当的参数初始值以便计算能够收敛并找到最优解。如果设定的参数初始值不当则计算难以收敛,或结果不是全局最优解。在实际应用当中,对大多数用户来说,给出(或猜出)恰当的初始值并不是一件容易的事,特别是在待估计的参数较多情况下,更无异于是场噩梦。
作为通用的统计建模工具,须克服非线性回归模型参数估计依赖于参数的初始值的设定的难题。应能在不需给出非线性回归方程系数初始值的情形下,以较高的可能性得到全局最优解,这对用户来说是至关重要的。
在DPS系统中,今年以来开发了一套基于演化计算思想和局部数值寻优技术相结合的全局优化算法。较好地解决了参数估计无需用户给出恰当初始值问题。在用户使用时无需提供初始值。DPS从自己设定的随机初始值开始,可估计得到非线性回归参数的正确结果、即全局最优估计。
应用DPS提供的全局优化算法对NIST提供的27个非线性拟合测试题,可不依赖于初始值而得到最优解。同时对数据拟合软件1stOpt的《优化•拟合•建模:1stOpt应用详解》一书所有非线性拟合数据例子进行测试,均能得到和1stOpt一样的最优解。
改进后的DPS非线性回归,在编辑、选定数据和公式后,进入菜单,选择“数学模型”→“一般非线性回归模型”,即刻进入用户分析界面。该用户界面里面有2个页面,第一个页面是模型检查与参数设置(下图)。
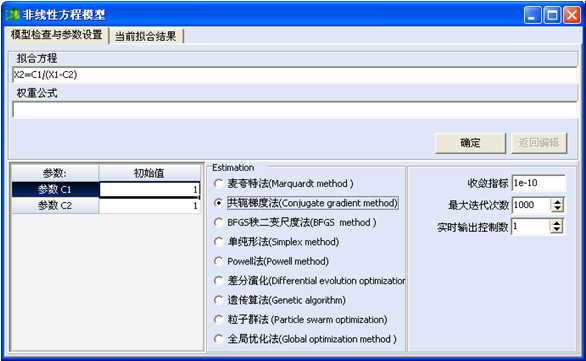
目前DPS系统提供了10余种非线性回归方程参数估计方法,方法的排列大体分4类:第一类是麦夸特法、共轭梯度法和BFGS秩二变尺度法。它们拟合速度快、精度高、但对初始值依赖程度也最大。第二类是单纯形法和Powell法。它们在优化时无需求导数,速度亦较快,精度高,对初始值依赖程度前面几种方法宽松一些。但有些复杂模型在初始值不当时得不到全局优化结果。第三类是差分演化法、遗传算法和粒子群法等仿生、智能的全局优化技术。它们的参数初始值可随机给出,但是迭代计算速度慢、达到一定精度需较长时间,模型复杂、数据较多时需要时间更长,因此很少有实用性。
在菜单最后一个是结合演化计算思想和数值优化技术的全局优化算法。它可较好地解决参数估计初始值问题;且计算速度较快,可在大多数情况下估计得到非线性回归参数的全局最优解。以数据拟合软件1stOpt在《优化×拟合×建模:1stOpt应用详解》一书所有非线性拟合数据例子进行测试,可以得到文献中所有例子的最优解。这里以两例难度较大的非线性拟合数据集为例,进行全局优化算法的建模参数估计。
下面这组数据,共有4个峰,最后一个峰仅有三个数据点。待拟合的非线性回归方程为:
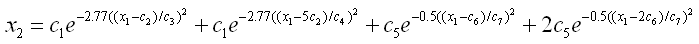
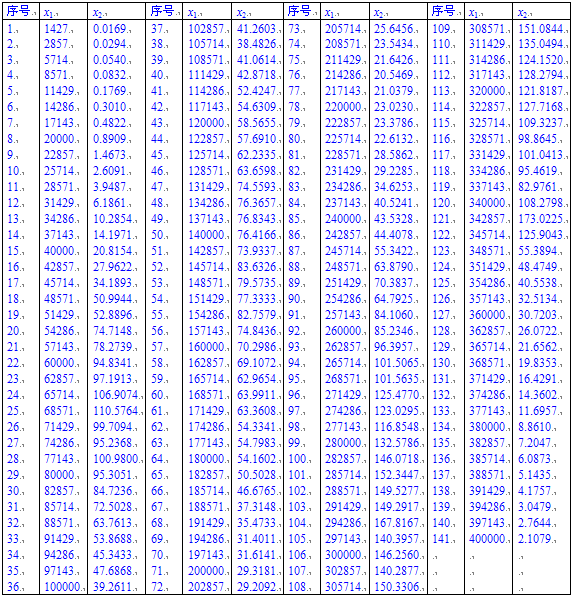
应用一般的软件,很难得到正确的解,因为很难给出合适的参数初始值。在DPS中只要将数据两列编辑、用鼠标选中,并在下面公式编辑框中,在一行里面写入如下拟合的方程式:
x2=c1*exp(-2.77*((x1-c2)/c3)^2)+c1*exp(-2.77*((x1-5*c2)/c4)^2)+c5*exp(-0.5*((x1-c6)/c7)^2)+2*c5*exp(-0.5*((x1-2*c6)/c7)^2)
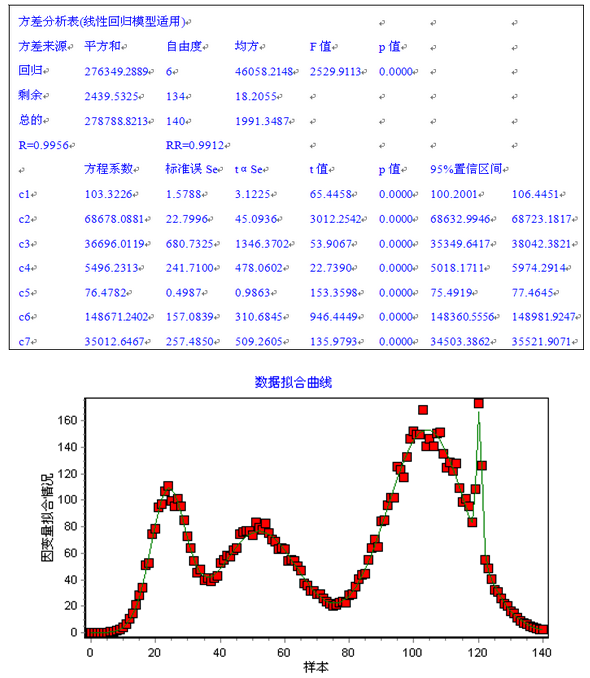
然后进入菜单,选择“数学模型”→“一般非线性回归模型”后,执行用户界面最下面的“全局优化算法”,无需给出初始值,系统经迭代可获得各参数估计值、统计检验以及拟合图如下:
另一组数据,两个变量,x1分别为-80,-60,-46,-36,-25,-17, -13,-10,-8,-6.3, 6.3, 8, 10, 13, 17, 25, 36, 46, 60和80;x2分别为0.15, 0.30, 0.5417, 0.5833, 1.40, 3.50, 6,13, 14. 50, 8.095, 8.095, 14.50, 13,6, 3.50, 1.40, 0.5833, 0.5417, 0.30和0.15。待拟合的非线性回归方程为:

在没有恰当的初始值时,亦很难估计得到正确系数。
在DPS中只要将数据x1和x2分两列编辑、用鼠标选中,并在下面公式编辑框中写入如下拟合方程式
x2=c1/(1+c2*(x1*x1)^c3+c4*exp(c5*(x1*x1)^c6))
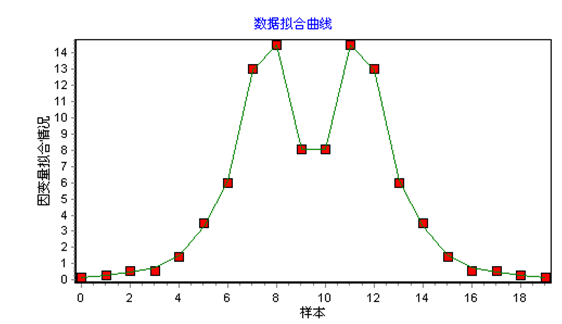
然后进入菜单,选择“数学模型”→“一般非线性回归模型”后,执行用户界面最下面的“全局优化算法”,无需给出初始值,系统经迭代可获得各参数估计值、统计检验结果。该例拟合精度高,其相关系数R=0.9998,决定系数R2=0.9996。各个系数估计值分别为c1=-1.4790754E+01,c2=-3.4958680E-02,c3=8.9331770E-01,c4=-2.1584687E+00,c5=-2.9469993E-09,c6=4.7873056E+00。观测值和拟合曲线如下图所示。
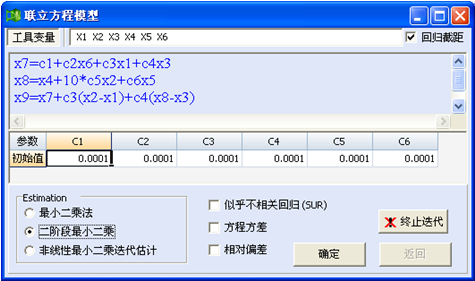
联立方程模型功能更新
发布日期:2013-02-15联立方程模型,我们为用户提供了更一般的联立方程模组的参数估计方法,以解决更为广泛的联立方程组形式的估计问题。这里的联立方程组中的简化方程包括线性方程、非线性方程及其差分方程。这类模型的参数求解问题更为复杂。提供了联立方程二阶段最小二乘方法估计、三阶段最小二乘方法、似乎不相关回归(Seemingly Unrelated Regression, SUR)分析等(如下图)。