DPS数据处理系统v16.05
完善的统计分析功能涵盖了几乎所有的统计分析内容,是目前国内统计分析功能最全软件包。但我们仍然期待着您的建议,不断地吸纳新的统计方法,使DPS系统的统计分析功能更加完善。
更新日志
改进复合中心设计(二次正交旋转组合、二次通用组合、二次正交回归)的实验设计操作
发布日期:2010-10-22对复合中心设计、均匀设计、饱和设计及Box-Behnken设计试验结果建模的统计分析功能进行了改进和增补。增加了模型优化的典型分析、及处理含区组设计的二次正交回归组合(中心复合)设计、以及应用逐步回归挑选重要因子等功能。优化模块在“试验统计”->“试验优化分析”里面。并根据增补内容,对教材的第10章进行了修改、增订,点击这里可下载增订后的《DPS数据处理系统-试验设计、统计分析及数据挖掘(第10章)》教材。
DPS高级版增加了多个变量相关系数计算功能
发布日期:2010-09-21DPS增加了计算多个变量相关系数的功能,并允许有缺失的数据的情形。计算相关系数时,可以允许变量是分类变量。分类变量和分类变量之间,我们采用极大似然估计计算变量间的多项相关系数;分类变量和连续变量之间,计算多序列相关系数;在连续变量之间计算Pearson相关系数。这样,各种类型的变量指标都可计算相关系数,以方便用户在相关系数矩阵基础上进行因子分析等多元统计分析。计算相关系数数据格式如下:

相关分析功能在"多元分析"->"相关分析"->“多变量相关分析”菜单下。上面数据,在执行多变量相关分析功能后,系统出现如下用户界面,提示用户选定某变量是否是分类变量。
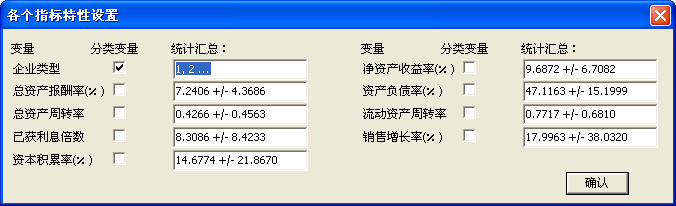
用户选定,并点击“确定”按钮后,系统给出如下相关分析结果。结果很详细,在数据分析是对用户很有帮助。
DPS高级版增强了图形处理功能,所有数据处理结果里面的图形都输出到电子工作表之中,原来在DPS的输出结果中,只有数值。根据用户的建议,我们在分析结果中增加了图形的输出,如多元分析里面,回归分析的误差诊断图、拟合曲线图,聚类分析中的树状图,判别分析中的判别得分,以及主成份得分图等。极大地方便了用户。使得DPS的输出结果“图文并茂”。
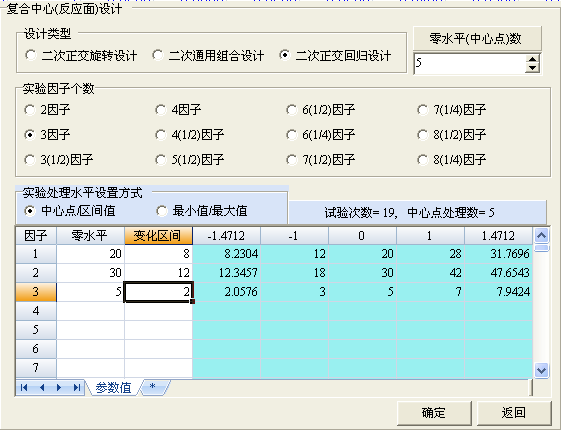
重新设计了二次正交回归组合(中心复合)设计的用户界面,以便于用户灵活地进行实验设计、调整实验处理水平值。所见即所得地开展实验设计。
成功解决因子分析中因子模型统计问题
发布日期:2010-05-15目前在社会科学等领域广泛应用的因子 分析中的公因子模型,理应和我们进行回归分析所建立的回归模型一样,在建立回归方程之后对模型进行统计检验,只有在通过统计检验之后才能将它用来解释模型的专业意义。
但遗憾的是,一直到现在,因子模型的统计检验问题没能解决。没有统计检验的因子模型,充其量只能算是一个描述性的数学表达式,而不是真正的理论模型。以至于R.A. Johnson & D.W.Wichern(2007) 在他们的专著“Applied Multivariate Statistical Analysis(第6版)”中因子分析这一章结尾时写道:
“因子分析是十分主观的,在许多出版的资料中,因子分析模型都用少数可阐述因子提供了合理解释。实际上,绝大多数因子分析并没有产生如此明确的结果。不幸的是,评价因子分析质量的法则尚未很好量化,质量问题只好依赖一个“哇!”准则,如果在仔细检查因子分析的时候,研究人员能够喊出“哇,我明白这些因子”的时候,就可看着是成功运用了因子分析方法。”
要使因子分析成为一种真正的科学的统计方法,因子模型的统计检验是必不可少的。
值得庆幸的是:经过我们的努力,这一现状已一去不复返了——因子分析模型的统计检验问题得到了解决。因子分析时,在确定取多少个公因子 、及采用哪种因子模型参数估计方法(极大似然法、未加权最小二乘、主成份法、主因子法, ... )建立公因子模型之后,就可以对该因子模型,像回归分析一样进行统计检验(相当于回归分析的F检验),并给出因子模型精度的拟合指数(相当与回归方程的决定系数)。 统计检验细节已撰写相关论文(已投稿,待发表)。
该功能已加入到我们开发的DPS统计软件中。DPS进行因子分析时将给出因子模型检验的主要结果,即显著水平p值、拟合指数Q值(因论文尚未正式发表,更多的结果即内容细节不便给出)。结果判读规则是,只有当p值大于0.05时,因子模型才可以应用(注意:这一点不像回归分析,p<0.05时回归模型才可用)、p值越大模型越好;拟合指数Q值越大,因子模型精度越高。p值和Q值大致呈正相关趋势,但没有严格的对应关系。直观地来讲,你可以将p值和Q值分别理解为模型的准确度和精确度。
DPS提供的因子模型统计检验功能,可供大家试用。
为庆祝因子分析模型统计检验技术的研究成功,我们将因子分析统计检验功能加入到DPS数据处理系统高级版、系统升级为v12.01。目前,只有使用DPS进行因子分析,才能保证得到正确、“最优”的结果。
因子分析功能更新
发布日期:2010-04-08因子分析(factor analysis)是目前应用广泛的数据统计分析功能。目前几乎所有的统计软件都没有向用户提供交互式的确定公因子个数功能。DPS系统中的因子分析功能,我们重新设计了其用户界面, 增加了Parallel analysis (PA)分析线(图中红色虚线),据称应用该线来确定公因子个数更好。并几乎全部重新写了其程序源代码,尤其是初始因子模型参数的极大似然(Maximum likelihood)估计,经重新设计算法、优化程序,因子模型参数估计的准确度、精确度有很大提高。
改进后的用户界面如下:
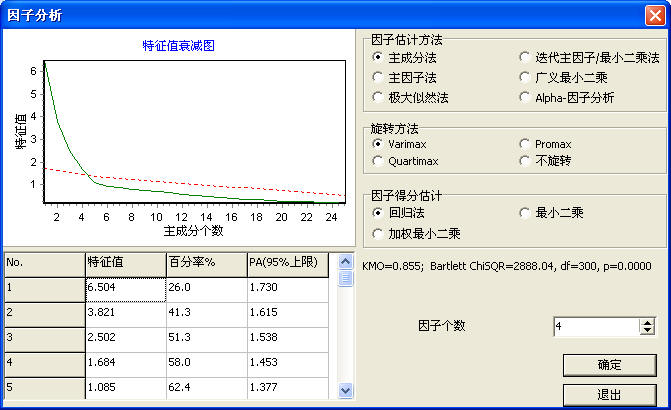
因子的极大似然估计算法的改进,比以前版本速度加快,更主要的是参数估计精度提高,特别是当有Heywood现象存在时。经对10多组例子数据的测试,改进后的DPS中的因子分析,极大似然法的对公因子模型初始值估计结果的精度达到了国外大型统计软件的水准,有时结果更优一些,如下面的例子是Robert C. MacCallum(2004)在“因子分析100年”学术会议上人工产生的12个变量的因子分析数据,以及Roberts和Lattin(1991)调查的有关食物的25个指标(变量)数据,采用极大似然估计进行因子分析,其最小化目标函数公式如下:
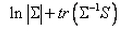
从计算结果可以看出,大部分情况下,DPS和SAS的结果的目标函数值十分接近。但是obert C. MacCallum(2004)的数据提取5个公因子时,DPS的最小化目标函数值看来更小、更好一些。
通过这段时间对主成分分析和因子分析的研究,体会是:
主成分分析:
1.用较少的变量表示原来的样本;
2.目的是样本数据信息损失最小的原则下,对高维变量进行降维。
3.参数估计,一般是求相关矩阵的特征值和相应的特征向量(主成分分析法),取前几个计算主成分。
4.应用:应用较少变量来解释各个样本的特征(数据降维、综合平价)。
因子分析:
1.用较少的因子表示原来的变量;
2.目的是尽可能保持原变量相互关系(结构)原则下;寻找变量的公共因子。
3.参数估计,指定几个公因子,将其还原成相关系数矩阵,在和原样本相关矩阵最相似(最大似然法)原则下,估计各个公因子的估计值。
4.应用:找到具有本质意义的少量因子来归纳原来变量的特征(因子降维、潜在因子)。
如果说主成份分析和因子分析的联系,那么可以说:因子分析中公因子模型参数估计方法很多,其中有一种公因子模型参数估计方法是“主成份分析法”。
二次多项式回归(反应面分析)中增加了典范分析(Canonical analysis)功能。
发布日期:2010-02-23“实验优化分析”中的“二次多项式回归”是DPS用户用得最多的功能之一。这是因为实验数据的优化建模,亦即对实验结果进行二次多项式回归寻找最优的目标条件,是各行各业用得最多的。一般国内教材在介绍回归优化建模时,很少提及典范分析。DPS提供的典范分析功能,可辅助用户在分析最优目标函数点时作为参考:如果稳定点就是最优点,那么理论上该最优点是最好的。但一般情况并非如此,这时要结合典范分析结果对最优点进行分析。典范分析结果例子如下表:
“积分回归”增加了数据标准化功能。
“马尔可夫链”分析功能进行了改进,增加了马尔可夫性质的卡方检验功能,并增加、改进了用户界面。